4 Einführung ins tidyverse
Für dieses Kapitel benötigen Sie die folgenden Packages und Data Frames:
## ── Attaching core tidyverse packages ──────────────────
## ✔ dplyr 1.1.4 ✔ readr 2.1.5
## ✔ forcats 1.0.0 ✔ stringr 1.5.1
## ✔ ggplot2 3.5.0 ✔ tibble 3.2.1
## ✔ lubridate 1.9.3 ✔ tidyr 1.3.1
## ✔ purrr 1.0.2
## ── Conflicts ───────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors##
## Attaching package: 'magrittr'
##
## The following object is masked from 'package:purrr':
##
## set_names
##
## The following object is masked from 'package:tidyr':
##
## extracturl <- "http://www.phonetik.uni-muenchen.de/~jmh/lehre/Rdf"
asp <- read.table(file.path(url, "asp.txt"))
int <- read.table(file.path(url, "intdauer.txt"))
vdata <- read.table(file.path(url, "vdata.txt"))Nutzen Sie die Methoden aus Kapitel 3.2, um sich mit den einzelnen Data Frames vertraut zu machen!
Das tidyverse ist eine Sammlung von Packages, die bei unterschiedlichen Aspekten der Datenverarbeitung helfen. Wir werden uns im Verlauf der nächsten Kapitel mit einigen dieser tidyverse-Packages beschäftigen. Wenn Sie das tidyverse laden, sehen Sie folgendes:
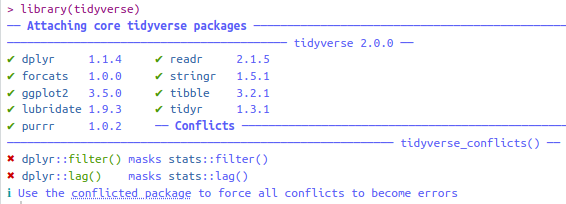
Zum tidyverse in der Version 2.0 gehören die neun dort aufgelisteten Packages (dplyr, forcats, ggplot2, lubridate, purrr, readr, stringr, tibble, tidyr). All diese Pakete können Sie auch einzeln laden, wenn Sie das möchten. Zusätzlich wird angezeigt, dass es zwei Konflikte gibt: Die Notation dplyr::filter() bedeutet “die Funktion filter() aus dem Paket dplyr”. Diese Funktion überschreibt die Funktion filter() aus dem Paket stats (das ist ein Paket, das den NutzerInnen ohne vorheriges Laden mittels library() immer zur Verfügung steht). Funktionen aus verschiedenen Paketen können sich gegenseitig überschreiben, wenn sie denselben Funktionsnamen haben, wie z.B. filter(). Wenn man nun also filter() verwendet, wird die Funktion von dplyr verwendet, nicht die Funktion von stats. Wenn man explizit die Funktion von stats verwenden will, kann man die obige Notation verwenden, also stats::filter().
Viele Funktionen aus dem tidyverse dienen dazu, traditionelle R Notationen abzulösen. Diese traditionellen Notationen sind häufig recht sperrig; tidyverse-Code hingegen ist leicht zu lesen und zu schreiben. Wir verwenden tidyverse, um Data Frames aufzuräumen, zu filtern oder zu verändern.
4.1 Pipes
Dazu müssen wir zuerst lernen, wie die tidyverse-Syntax funktioniert:
## d Wort Vpn Kons Bet
## 1 26.18 Fruehlingswetter k01 t un
## 2 23.06 Gestern k01 t un
## 3 26.81 Montag k01 t un
## 4 14.75 Vater k01 t un
## 5 42.38 Tisch k01 t be
## 6 21.56 Mutter k01 t unWir beginnen den Code immer mit dem Date Frame und hängen dann einfach alle Funktionen, die wir auf den Data Frame anwenden wollen, in chronologischer Reihenfolge an den Data Frame. Zwischen jeder Funktion steht die Pipe %>%. Die Pipe nimmt immer das, was links von der Pipe steht, und reicht es weiter an die Funktion, die rechts von der Pipe steht. Im Code oben wird also die Funktion head() auf den Data Frame asp angewendet. Dies ist genau dasselbe wie:
## d Wort Vpn Kons Bet
## 1 26.18 Fruehlingswetter k01 t un
## 2 23.06 Gestern k01 t un
## 3 26.81 Montag k01 t un
## 4 14.75 Vater k01 t un
## 5 42.38 Tisch k01 t be
## 6 21.56 Mutter k01 t unIn der tidyverse-Schreibweise mit der einfachen Pipe wird der Data Frame nicht verändert; das Ergebnis des Codes wird einfach in der Konsole ausgegeben. Wenn Sie das Ergebnis einer tidyverse-Pipe in einer Variable abspeichern wollen, nutzen Sie die übliche Notation mit dem Zuweisungspfeil <-:
## [1] 2892Das Besondere ist, dass Sie so viele Funktionen mit der Pipe aneinanderhängen können wie Sie wollen. Die Funktionen werden immer auf das Ergebnis der vorherigen Funktion angewendet, wie wir gleich sehen werden. Innerhalb der Funktionen können wir dank der Pipe auf alle Spalten des Data Frames einfach mittels ihres Namens zugreifen.
4.2 Daten manipulieren mit dplyr
Die wichtigsten Funktionen, die Sie in Ihrem Alltag mit R brauchen werden, stammen aus dem Package dplyr. Wir unterteilen hier nach verschiedenen Arten von Operationen, die Sie auf Data Frames ausführen können.
4.2.1 Filtering
Häufig werden wir aus Data Frames bestimmte Zeilen und/oder Spalten auswählen. Das Auswählen von Zeilen erfolgt mit der Funktion filter(). Als Argument(e) bekommt die Funktion einen oder mehrere logische Ausdrücke. Hierfür benötigen Sie die logischen Operatoren aus Kapitel 2.4. Wenn Sie aus dem Data Frame asp alle Zeilen auswählen wollen, bei denen in der Spalte Wort “Montag” steht, nutzen Sie beispielsweise den Operator ==:
## d Wort Vpn Kons Bet
## 3 26.81 Montag k01 t un
## 63 17.75 Montag k01 t un
## 123 45.12 Montag k02 t un
## 182 40.50 Montag k03 t un
## 241 33.00 Montag k04 t un
## 300 32.69 Montag k04 t un
## 359 50.82 Montag k05 t un
## 476 27.93 Montag k06 t un
## 537 17.25 Montag k61 t un
## 597 21.13 Montag k62 t un
## 656 20.75 Montag k62 t un
## 2078 105.94 Montag k70 t un
## 2079 17.56 Montag k70 t un
## 2080 22.25 Montag k70 t un
## 2155 60.25 Montag K19 t un
## 2156 14.87 Montag K20 t un
## 2157 17.56 Montag K20 t un
## 2231 47.31 Montag K74 t un
## 2232 34.94 Montag K74 t un
## 2233 35.44 Montag K74 t un
## 2310 22.62 Montag k61 t un
## 2311 16.43 Montag k61 t un
## 2312 29.31 Montag k61 t un
## 2391 50.31 Montag k61 t un
## 2392 33.12 Montag k61 t un
## 2393 39.68 Montag k61 t un
## 2403 42.88 Montag k61 t un
## 2424 35.44 Montag k62 t un
## 2506 11.25 Montag k62 t un
## 2528 8.06 Montag k62 t un
## 2604 33.94 Montag dlm t un
## 2624 29.87 Montag dlm t un
## 2704 30.32 Montag dlm t un
## 2725 21.93 Montag dlm t un
## 2800 49.12 Montag hpt t un
## 2821 24.87 Montag hpt t unAlle Zeilen, bei denen die Dauer d kleiner ist als 10 ms, erhält man mit folgendem Ausdruck:
## d Wort Vpn Kons Bet
## 180 9.130 Fruehlingswetter k03 t un
## 205 8.440 verstauchter k03 t un
## 540 6.688 Mutter k61 t un
## 773 8.000 Butter k64 t un
## 895 7.060 Buttergeschichte k66 t un
## 982 9.500 Butter k66 t un
## 999 8.300 Butter K22 t un
## 1142 9.750 Vater K30 t un
## 1155 8.630 Schwester K61 t un
## 1170 5.690 maechtig K62 t un
## 1294 9.690 Butter k07 t un
## 1362 8.870 Freitag k08 t un
## 1548 6.500 Vater k10 t un
## 1564 8.750 spaeter k11 t un
## 1565 5.250 Sonntags k11 t un
## 2507 6.570 unterbrechen k62 t un
## 2528 8.060 Montag k62 t un
## 2542 9.500 Samstag k62 t un
## 2580 8.880 samstags k62 t unSie können natürlich auch mehrere logische Ausdrücke miteinander verbinden, nämlich mittels den Operatoren für “und” & oder für “oder” |. Mit dem folgenden Ausdruck werden nur Zeilen zurückgegeben, bei denen die Versuchsperson Vpn entweder “k01” oder “k02” oder “k03” ist und der Konsonant Kons ungleich “t”:
## d Wort Vpn Kons Bet
## 7 50.00 konnte k01 k un
## 8 78.12 Kaffee k01 k be
## 11 64.13 Broetchenkorb k01 k be
## 12 48.94 keinen k01 k be
## 13 59.00 Kuchen k01 k be
## 16 56.00 einkaufen k01 k be
## 19 34.37 Zucker k01 k un
## 20 55.75 Suessigkeiten k01 k un
## 21 55.62 kaufen k01 k be
## 22 55.94 Konserven k01 k un
## 23 61.81 Kasse k01 k be
## 28 47.25 Kartoffeln k01 k un
## 31 37.62 Kaffee k01 k be
## 33 54.19 Koennen k01 k un
## 35 35.49 Dickicht k01 k un
## 40 59.44 Kuechenofen k01 k be
## 42 64.50 kocht k01 k be
## 48 69.19 Karten k01 k be
## 49 58.69 Fahrkarten k01 k be
## 53 30.82 Acker k01 k un
## 57 95.13 kurz k01 k be
## 58 57.38 verkuendet k01 k be
## 59 72.00 kommen k01 k be
## 67 37.75 konnte k01 k un
## 68 52.69 Kaffee k01 k be
## 71 71.43 Broetchenkorb k01 k be
## 72 51.75 keinen k02 k be
## 73 70.82 Kuchen k02 k be
## 76 68.19 einkaufen k02 k be
## 79 17.38 Zucker k02 k un
## 80 50.25 Suessigkeiten k02 k un
## 81 43.07 kaufen k02 k be
## 82 35.62 Konserven k02 k un
## 83 59.25 Kasse k02 k be
## 88 44.94 Kartoffeln k02 k un
## 91 34.44 Kaffee k02 k be
## 93 35.62 Koennen k02 k un
## 95 30.69 Dickicht k02 k un
## 100 72.32 Kuechenofen k02 k be
## 102 33.75 kocht k02 k be
## 108 61.06 Karten k02 k be
## 109 50.82 Fahrkarten k02 k be
## 113 23.93 Acker k02 k un
## 117 67.87 kurz k02 k be
## 118 35.62 verkuendet k02 k be
## 119 44.56 kommen k02 k be
## 127 39.87 konnte k02 k un
## 128 46.00 Kaffee k02 k be
## 131 67.57 Broetchenkorb k02 k be
## 132 58.25 keinen k02 k be
## 133 58.81 Kuchen k02 k be
## 136 54.94 einkaufen k02 k be
## 139 30.88 Zucker k02 k un
## 140 49.18 Suessigkeiten k02 k un
## 141 63.44 kaufen k02 k be
## 142 45.25 Konserven k02 k un
## 143 50.50 Kasse k02 k be
## 148 54.31 Kartoffeln k03 k un
## 151 53.25 Kaffee k03 k be
## 153 34.00 Koennen k03 k un
## 155 47.82 Dickicht k03 k un
## 160 50.56 Kuechenofen k03 k be
## 162 38.38 kocht k03 k be
## 168 62.43 Karten k03 k be
## 169 36.94 Fahrkarten k03 k be
## 172 46.69 Acker k03 k un
## 176 43.38 kurz k03 k be
## 177 54.75 verkuendet k03 k be
## 178 53.75 kommen k03 k be
## 186 32.56 konnte k03 k un
## 187 41.81 Kaffee k03 k be
## 190 56.81 Broetchenkorb k03 k be
## 191 52.93 keinen k03 k be
## 192 59.88 Kuchen k03 k be
## 195 46.13 einkaufen k03 k be
## 198 29.51 Zucker k03 k un
## 199 43.13 Suessigkeiten k03 k un
## 200 36.75 kaufen k03 k be
## 201 33.82 Konserven k03 k un
## 202 60.69 Kasse k03 k be
## 206 32.25 Kartoffeln k03 k un
## 209 48.00 Kaffee k03 k be
## 211 33.19 Koennen k03 k un
## 213 56.81 Dickicht k03 k un
## 218 65.37 Kuechenofen k03 k be
## 220 40.81 kocht k03 k beDie Zeilen in einem Data Frame sind normalerweise durchnummeriert, d.h. die Zeilen haben einen Index. Wenn wir mittels des Index Zeilen auswählen wollen, nutzen wir slice() bzw. die verwandten Funktionen slice_head(), slice_tail(), slice_min() und slice_max(). Die Funktion slice() bekommt als Argument den Index der auszuwählenden Zeilen:
## d Wort Vpn Kons Bet
## 4 14.75 Vater k01 t un## d Wort Vpn Kons Bet
## 1 26.18 Fruehlingswetter k01 t un
## 2 23.06 Gestern k01 t un
## 3 26.81 Montag k01 t un
## 4 14.75 Vater k01 t un
## 5 42.38 Tisch k01 t be
## 6 21.56 Mutter k01 t un
## 7 50.00 konnte k01 k un
## 8 78.12 Kaffee k01 k be
## 9 53.63 Tassen k01 t be
## 10 45.94 Teller k01 t beDie Funktionen slice_head() und slice_tail() bekommen als Argument die Anzahl der Zeilen n, die, angefangen bei der ersten bzw. der letzten Zeile, ausgewählt werden sollen.
## d Wort Vpn Kons Bet
## 1 26.18 Fruehlingswetter k01 t un
## 2 23.06 Gestern k01 t un## d Wort Vpn Kons Bet
## 2890 24.94 vormittags kko t un
## 2891 21.93 Richtung kko t un
## 2892 51.94 Verkehrt kko k beDie Funktionen slice_min() und slice_max() geben die n Zeilen zurück, die die niedrigsten bzw. höchsten Werte in einer Spalte haben. Wenn n nicht angegeben wird, wird automatisch n = 1 verwendet, es wird also nur eine Zeile zurückgegeben.
Weiterführende Infos: Defaults für Argumente
Wenn man bestimmte Argumente in Funktionen nicht spezifiziert, werden häufig sog. defaults verwendet. Schauen Sie sich zum Beispiel die Hilfeseite der Funktion seq() an. Dort wird die Funktion mit ihren Argumenten wie folgt aufgeführt:

Die Argumente from und to haben den default-Wert 1. Und da dies die einzigen obligatorischen Argumente sind, können Sie die Funktion auch völlig ohne Angabe der Argumente ausführen:
## [1] 1Auch das Argument by hat einen default-Wert, der anhand der Werte von to, from und length.out berechnet wird, falls der/die NutzerIn keinen anderen Wert eingibt.
Meist finden Sie die default-Werte für die Argumente einer Funktion auf der Hilfeseite unter Usage, manchmal stehen die default-Werte auch erst in der Beschreibung der Argumente darunter.
Im folgenden zeigen wir Beispiele für die zwei Funktionen, die sich auf die Dauer in Spalte d des Data Frames asp beziehen.
## d Wort Vpn Kons Bet
## 1565 5.25 Sonntags k11 t un## d Wort Vpn Kons Bet
## 1565 5.250 Sonntags k11 t un
## 1170 5.690 maechtig K62 t un
## 1548 6.500 Vater k10 t un
## 2507 6.570 unterbrechen k62 t un
## 540 6.688 Mutter k61 t un## d Wort Vpn Kons Bet
## 2063 138.8 Kiel k70 k be## d Wort Vpn Kons Bet
## 2063 138.8 Kiel k70 k be
## 2843 129.7 Kiel hpt k be
## 1006 116.5 Ladentuer K23 t be
## 2070 111.6 Tagen k70 t be
## 1456 111.4 kauen k09 k beDiese beiden Funktionen lassen sich sogar auf Spalten anwenden, die Schriftzeichen enthält. In diesem Fall wird alphabetisch vorgegangen.
## d Wort Vpn Kons Bet
## 51 47.63 Abteil k01 t be
## 111 56.25 Abteil k02 t be
## 171 56.81 Abteil k03 t be
## 229 31.63 Abteil k04 t be
## 288 67.31 Abteil k04 t be
## 347 76.25 Abteil k05 t be
## 406 38.07 Abteil k05 t be
## 463 52.62 Abteil k06 t be
## 524 46.93 Abteil k61 t be
## 585 35.18 Abteil k61 t be
## 644 47.00 Abteil k62 t be
## 703 79.37 Abteil k63 t be## d Wort Vpn Kons Bet
## 2444 80.75 zurueckkommen k62 k be
## 2546 73.44 zurueckkommen k62 k be
## 2641 53.30 zurueckkommen dlm k be
## 2743 63.12 zurueckkommen dlm k be
## 2838 79.63 zurueckkommen hpt k beDa es jeweils mehrere Zeilen gibt, wo Wort den niedrigsten (“abkaufen”) bzw. höchsten Wert (“Zwischenstop”) hat, werden all diese Zeilen zurückgegeben (trotz n = 1).`
4.2.2 Selecting
Für das Auswählen von Spalten ist die Funktion select() da, die auf verschiedene Art und Weise benutzt werden kann. Als Argumente bekommt diese Funktion die Spaltennamen, die ausgewählt werden sollen. In den folgenden Beispielen sehen Sie außerdem zum ersten Mal, wie man mehrere Funktionen mit einfachen Pipes aneinander hängen kann, denn wir nutzen nach select() hier noch slice(1), damit der Output der Funktionen nicht so lang ist.
## Vpn
## 1 k01## Vpn Bet
## 1 k01 un## d Wort Vpn Kons
## 1 26.18 Fruehlingswetter k01 t## Bet
## 1 un## d Vpn Kons Bet
## 1 26.18 k01 t unInnerhalb der Funktion select() können die Funktionen starts_with() und ends_with() sehr praktisch sein, wenn Sie alle Spalten auswählen wollen, deren Namen mit demselben Buchstaben oder derselben Buchstabenfolge beginnen bzw. enden. Dies demonstrieren wir anhand des Data Frames vdata, der folgende Spalten hat:
## [1] "X" "Y" "F1" "F2" "dur" "V"
## [7] "Tense" "Cons" "Rate" "Subj"starts_with() erlaubt es uns, die beiden Spalten F1 und F2 auszuwählen, weil beide mit “F” beginnen:
## F1 F2
## 1 313 966Wie auch beim Filtern, können Sie mit den logischen Operatoren & bzw. | die Funktionen starts_with() und ends_with() verbinden. Hier wählen wir (auf etwas umständliche Weise) die Spalte F1 aus:
## F1
## 1 313Es wird ab und zu vorkommen, dass wir (nach einer ganzen Reihe an Funktionen) nur eine Spalte ausgegeben haben wollen, aber nicht als Spalte (bzw. um genau zu sein: als Data Frame mit nur einer Spalte), sondern einfach als Vektor. Dafür nutzen wir pull(). Im folgenden Beispiel wählen wir zuerst die ersten zehn Zeilen von asp aus und lassen uns davon dann die Spalte Bet als Vektor ausgeben:
## [1] "un" "un" "un" "un" "be" "un" "un" "be" "be" "be"An der Ausgabe sehen Sie, dass es sich bei Bet um einen Vektor handelt.
4.2.3 Mutating
Mit Mutating können wir Spalten an Data Frames anhängen oder verändern. Der Befehl heißt mutate() und bekommt als Argumente den gewünschten neuen Spaltennamen mit den Werten, die in der Spalte stehen sollen. Wenn mehrere Spalten angelegt werden sollen, können Sie sie innerhalb der Funktion aneinanderreihen. Folgender Code legt zum Beispiel zwei neue Spalten namens F1 und F2 im Data Frame int an:
## Vpn dB Dauer
## 1 S1 24.50 162
## 2 S2 32.54 120
## 3 S2 38.02 223
## 4 S2 28.38 131
## 5 S1 23.47 67
## 6 S2 37.82 169int %>% mutate(F1 = c(282, 277, 228, 270, 313, 293, 289, 380, 293, 307, 238, 359, 300, 318, 231),
F2 = c(470, 516, 496, 530, 566, 465, 495, 577, 501, 579, 562, 542, 604, 491, 577))## Vpn dB Dauer F1 F2
## 1 S1 24.50 162 282 470
## 2 S2 32.54 120 277 516
## 3 S2 38.02 223 228 496
## 4 S2 28.38 131 270 530
## 5 S1 23.47 67 313 566
## 6 S2 37.82 169 293 465
## 7 S2 30.08 81 289 495
## 8 S1 24.50 192 380 577
## 9 S1 21.37 116 293 501
## 10 S2 25.60 55 307 579
## 11 S1 40.20 252 238 562
## 12 S1 44.27 232 359 542
## 13 S1 26.60 144 300 604
## 14 S1 20.88 103 318 491
## 15 S2 26.05 212 231 577Diese neuen Spalten werden nicht automatisch im Data Frame abgespeichert! Es gibt zwei Möglichkeiten, um die Spalten dauerhaft an den Data Frame anzuhängen. Die erste ist wie üblich mit dem Zuweisungspfeil. Wir erstellen hier eine neue Variable int_new, die den erweiterten Data Frame enthält; man hätte auch den originalen Data Frame überschreiben können, indem man statt int_new nur int schreibt.
int_new <- int %>%
mutate(F1 = c(282, 277, 228, 270, 313, 293, 289, 380, 293, 307, 238, 359, 300, 318, 231),
F2 = c(470, 516, 496, 530, 566, 465, 495, 577, 501, 579, 562, 542, 604, 491, 577))
int_new %>% head()## Vpn dB Dauer F1 F2
## 1 S1 24.50 162 282 470
## 2 S2 32.54 120 277 516
## 3 S2 38.02 223 228 496
## 4 S2 28.38 131 270 530
## 5 S1 23.47 67 313 566
## 6 S2 37.82 169 293 465Die zweite Möglichkeit ist die sogenannte Doppelpipe aus dem Paket magrittr: %<>%. Die Doppelpipe kann nur als erste Pipe in einer Reihe von Pipes eingesetzt werden (auch das werden wir noch sehen). Zudem muss als erstes Argument nach der Doppelpipe nicht mehr der Data Frame stehen, denn der steht schon links von der Doppelpipe.
int %<>% mutate(F1 = c(282, 277, 228, 270, 313, 293, 289, 380, 293, 307, 238, 359, 300, 318, 231),
F2 = c(470, 516, 496, 530, 566, 465, 495, 577, 501, 579, 562, 542, 604, 491, 577))
int %>% head()## Vpn dB Dauer F1 F2
## 1 S1 24.50 162 282 470
## 2 S2 32.54 120 277 516
## 3 S2 38.02 223 228 496
## 4 S2 28.38 131 270 530
## 5 S1 23.47 67 313 566
## 6 S2 37.82 169 293 465Es gibt zwei Funktionen, die sehr hilfreich innerhalb von mutate() sind, wenn eine neue Spalte auf den Werten einer bereits existierenden Spalte beruhen soll. Für binäre Entscheidungen nutzen Sie ifelse(), für nicht binäre Entscheidungen nutzen Sie case_when().
Nehmen wir an, Sie wollen eine weitere Spalte an den Data Frame int anhängen. Sie wissen, dass Versuchsperson “S1” 29 Jahre alt ist, Versuchsperson “S2” ist 33 Jahre alt. Sie wollen eine Spalte age anlegen, die genau das festhält. Dann benutzen Sie die Funktion ifelse() innerhalb von mutate(). ifelse() bekommt als Argumente zuerst einen logischen Ausdruck, dann den Wert, der eingesetzt werden soll, wenn der logische Ausdruck für eine Zeile wahr ist (TRUE), und zuletzt den Wert für Zeilen, für die der logische Ausdruck unwahr ist (FALSE). Um also die neue Spalte zu erstellen, wird für jede Zeile geprüft, ob die Versuchsperson “S1” ist; wenn ja, wird in die neue Spalte age der Wert 29 eingetragen, ansonsten der Wert 33.
## Vpn dB Dauer F1 F2 age
## 1 S1 24.50 162 282 470 29
## 2 S2 32.54 120 277 516 33
## 3 S2 38.02 223 228 496 33
## 4 S2 28.38 131 270 530 33
## 5 S1 23.47 67 313 566 29
## 6 S2 37.82 169 293 465 33
## 7 S2 30.08 81 289 495 33
## 8 S1 24.50 192 380 577 29
## 9 S1 21.37 116 293 501 29
## 10 S2 25.60 55 307 579 33
## 11 S1 40.20 252 238 562 29
## 12 S1 44.27 232 359 542 29
## 13 S1 26.60 144 300 604 29
## 14 S1 20.88 103 318 491 29
## 15 S2 26.05 212 231 577 33Bei nicht binären Entscheidungen wird statt ifelse() die Funktion case_when() eingesetzt. Diese Funktion bekommt so viele logische Ausdrücke und entsprechende Werte wie gewünscht. Zum Data Frame int wollen Sie eine weitere Spalte namens noise hinzufügen. Wenn in der Spalte dB ein Wert unter 25 Dezibel steht, soll in der Spalte noise “leise” stehen, bei Dezibelwerten zwischen 25 und 35 soll “mittel” und bei Dezibelwerten über 35 soll “laut” eingetragen werden. Die Schreibweise dieser Bedingungen ist wie folgt: Zuerst kommt der logische Ausdruck, dann die Tilde ~, und abschließend der einzutragende Wert, wenn der logische Ausdruck für eine Zeile wahr ist.
int %>% mutate(noise = case_when(dB < 25 ~ "leise",
dB > 25 & dB < 35 ~ "mittel",
dB > 35 ~ "laut"))## Vpn dB Dauer F1 F2 noise
## 1 S1 24.50 162 282 470 leise
## 2 S2 32.54 120 277 516 mittel
## 3 S2 38.02 223 228 496 laut
## 4 S2 28.38 131 270 530 mittel
## 5 S1 23.47 67 313 566 leise
## 6 S2 37.82 169 293 465 laut
## 7 S2 30.08 81 289 495 mittel
## 8 S1 24.50 192 380 577 leise
## 9 S1 21.37 116 293 501 leise
## 10 S2 25.60 55 307 579 mittel
## 11 S1 40.20 252 238 562 laut
## 12 S1 44.27 232 359 542 laut
## 13 S1 26.60 144 300 604 mittel
## 14 S1 20.88 103 318 491 leise
## 15 S2 26.05 212 231 577 mittel4.2.4 Renaming
Häufig ist es sinnvoll, Spalten umzubenennen und ihnen vernünftige Namen zu geben. (Generell ist es sinnvoll, den Spalten von Anfang an sprechende Namen zu geben, also Namen, die zweifelsfrei beschreiben, was in der Spalte zu finden ist – dies ist nicht trivial!)
Im Data Frame asp sind fast alle Spaltennamen Abkürzungen:
## [1] "d" "Wort" "Vpn" "Kons" "Bet"Jetzt benennen wir die Spalten um und speichern das Ergebnis mittels der Doppelpipe direkt im Data Frame asp ab. Hierzu benutzen wir rename(). Als Argumente bekommt die Funktion zuerst den gewünschten Spaltennamen, dann ein =, und dann den alten Spaltennamen. Sie brauchen die Spaltennamen nicht in Anführungszeichen zu setzen. Wenn Sie gleich mehrere Spalten umbenennen wollen, können Sie das einfach mit Komma getrennt in der Funktion angeben.
asp %<>% rename(Dauer = d,
Versuchsperson = Vpn,
Konsonant = Kons,
Betonung = Bet)
asp %>% colnames()## [1] "Dauer" "Wort" "Versuchsperson"
## [4] "Konsonant" "Betonung"4.3 Weitere Beispiele für komplexe Pipes
Wie Sie bereits gesehen haben, lassen sich viele Funktionen mit Pipes aneinanderhängen. Es ist dabei sehr wichtig, sich immer wieder vor Augen zu führen, dass jede Funktion auf das Ergebnis der vorherigen Funktion angewendet wird. Bei langen Pipes sollten Sie außerdem nach jeder Pipe einen Zeilenumbruch einfügen, weil dies die Lesbarkeit erhöht.
Die beiden folgenden Schreibweisen haben dasselbe Ergebnis und werfen auch keinen Fehler, aber sie gehen unterschiedlich vor. Im ersten Beispiel wird zuerst die Spalte Versuchsperson ausgewählt, dann wird die erste Zeile ausgewählt, beim zweiten Beispiel genau umgekehrt.
## Versuchsperson
## 1 k01## Versuchsperson
## 1 k01Das kann unter Umständen zu Fehlern führen, wenn Sie nicht genau aufpassen, in welcher Reihenfolge Sie Funktionen auf einen Data Frame anwenden. Sie möchten zum Beispiel aus dem Data Frame vdata die Spalte X auswählen, aber auch in Alter umbenennen. Dann wird der folgende Code einen Fehler werfen, weil sich die Funktion select() nicht mehr auf die Spalte X anwenden lässt, nachdem die Spalte bereits in Alter umbenannt wurde:
## Error in `select()`:
## ! Can't subset columns that don't exist.
## ✖ Column `X` doesn't exist.Der Fehler hier sagt Ihnen zum Glück genau, was falsch gelaufen ist. Richtig geht es also so (wir benutzen zusätzlich slice(1:10), damit der Output nicht so lang ist):
## Alter
## 1 52.99
## 2 53.61
## 3 55.14
## 4 53.06
## 5 52.74
## 6 53.30
## 7 54.37
## 8 51.20
## 9 54.65
## 10 58.42Ein weiteres Beispiel. Sie möchten aus dem Data Frame int die Dauerwerte erfahren, wenn F1 unter 270 Hz liegt.
## Error in UseMethod("filter"): no applicable method for 'filter' applied to an object of class "c('integer', 'numeric')"Dieser Fehler ist schon etwas kryptischer. Rekonstruieren wir also, was schief gelaufen ist. Aus dem Data Frame int haben wir die Spalte Dauer gezogen, die auch existiert. Dafür haben wir aber pull() verwendet, und pull() gibt Spalten in Form eines Vektors aus. Wir können das nochmal überprüfen wie folgt:
## [1] 162 120 223 131 67 169 81 192 116 55 252 232
## [13] 144 103 212## [1] "integer"Ja, dies ist ein Vektor mit integers. Oben haben wir dann versucht, auf diesen numerischen Vektor eine Funktion anzuwenden, die für Data Frames gedacht ist – daher der Fehler. Die Lösung ist in diesem Fall also, zuerst zu filtern, und dann die Werte ausgeben zu lassen:
## [1] 223 252 212Dies sind die Dauerwerte für die drei Zeilen, bei denen F1 unter 270 Hz liegt.
Zuletzt wollen wir hier noch ein Beispiel für eine komplexe Pipe mit der Doppelpipe am Anfang zeigen. Was wir also jetzt tun, wird sofort in den Data Frame geschrieben, und nicht einfach in der Konsole ausgegeben. Wir möchten die Spalte noise jetzt dauerhaft im Data Frame int anlegen, dann alle Zeilen auswählen, wo die Versuchsperson “S1” ist und die Dauer zwischen 100 und 200 ms liegt, und zuletzt die Spalten noise und Dauer sowie die ersten fünf Zeilen auswählen.
int %<>%
mutate(noise = case_when(dB < 25 ~ "leise",
dB > 25 & dB < 35 ~ "mittel",
dB > 35 ~ "laut")) %>%
filter(Vpn == "S1" & Dauer > 100 & Dauer < 200) %>%
select(Dauer, noise) %>%
slice_head(n = 5)
int## Dauer noise
## 1 162 leise
## 8 192 leise
## 9 116 leise
## 13 144 mittel
## 14 103 leiseDer Data Frame int besteht jetzt nur noch aus zwei Spalten und fünf Zeilen, und diese Aktion kann auch nicht rückgängig gemacht werden. Seien Sie also vorsichtig und überlegen Sie genau, ob Sie einen Data Frame mit dem Ergebnis einer Pipe überschreiben wollen.